Async Code in a Nutshell
So what are all these things about? Handling asynchronous code! But what is asynchronous (async) code to begin with? Consider this example.
const getUser = () => {
setTimeout(() => {
return { name: 'Max' }
}, 2000)
}
const user = getUser() // This doesn't actually fetch the user
console.log(user.name) // This won't workThis code won't work! We have a (ES6 arrow) function which executes setTimeout() and then tries to return an object after 2 seconds. That doesn't work because the getUser() function gets executed and its result gets used immediately. The immediate return value of the function is void though. Returning something after 2 seconds won't work. The same would be the case for functions where you reach out to a web server, access the file system or do something else which isn't finished immediately.
The reason why it doesn't work is that JavaScript code runs in a non-blocking way. That means, that it won't wait for async code to execute and return a value - it will only execute line for line until it's done. We can of course still work with asynchronous operations, it just doesn't work as attempted in the above code snippet.
Callbacks to the Rescue!
Since the above code doesn't work like that, we need to change something. Callbacks are the oldest way of working with data once it's there and continuing execution of the other code whilst the async code is executing.
Here's the revised code.
const getUser = cb => {
setTimeout(() => {
cb({ name: 'Max' })
}, 2000)
}
getUser(user => {
console.log(user.name) // Prints 'Max' after 2 seconds
})What changed? We're now not returning anything in getUser() - it wouldn't have worked anyways!
Instead, we now pass a callback function to getUser(). Inside getUser(), this callback function is received as a normal function argument and executed once the timer completes. The cool thing is, that we can now also pass an argument to the callback function.
const getUser = cb => {
setTimeout(() => {
cb({ name: 'Max' }) // <- Passing an argument to the callback function
}, 2000)
}Why is this helpful? It allows us to pass data to code which is defined somewhere else but which will only run once our timer completes! In the above example, it's an anonymous function but of course you could also use a named function.
// Use an anonymous function
getUser(user => {
console.log(user.name) // Prints 'Max' after 2 seconds
})
// Alternatively, use a named function:
getUser(handleUser) // <- This also works, just make sure to NOT execute the function here (handleUser() would be wrong!)
const handleUser = user => {
console.log(user.name) // Prints 'Max' after 2 seconds
}Notice that code execution doesn't stop whilst waiting for the timer.
const getUser = cb => {
setTimeout(() => {
cb({ name: 'Max' })
}, 2000)
}
getUser(user => {
console.log(user.name) // Prints 'Max' after 2 seconds
})
console.log('This prints before "Max" gets printed!') // <- This does indeed print before 'Max'So ... callbacks are pretty awesome, right? We can postpone code execution and work with data once we actually got it. And we don't even block the execution of our main program.
Welcome to Callback Hell
Unfortunately, it's not that easy. The idea behind callbacks indeed isn't bad and there is a reason why it's still getting used all over the web. But when working with a lot of dependent asynchronous operations, you quickly end up in callback hell. Consider this example.
const checkAuth = cb => {
// In reality, you of course don't have a timer but will probably reach out to a server
setTimeout(() => {
cb({ isAuth: true })
}, 2000)
}
const getUser = (authInfo, cb) => {
if (!authInfo.isAuth) {
cb(null)
return
}
setTimeout(() => {
cb({ name: 'Max' })
}, 2000)
}
checkAuth(authInfo => {
getUser(authInfo, user => {
console.log(user.name)
})
})This part here is pretty bad:
checkAuth(authInfo => {
getUser(authInfo, user => {
console.log(user.name)
})
})It could quickly grow to use multiple callbacks and nesting them into each other won't make your code easier to read, understand or maintain.
This problem is referred to as callback hell. It really can be a hell because you'll have a hard time changing one of your many layers of callbacks. Debugging it can be a pain and it certainly isn't readable anymore once you reach three or four levels of nesting.
Also don't forget error handling. It's not trivial to catch errors and handle them correctly when resting in callback hell. Indeed, you'll go even deeper into callback hell once you start handling different outcomes of your various asynchronous functions. Chances are, you want to run other asynchronous code if you encounter an error. Can you imagine where you'll end up with this?
Promising a Better Future
Callbacks are okay for single asynchronous operations but they certainly aren't perfect, we know that now. Fortunately, we're not the only ones discovering this issue. ES6 introduces a solution: Promises! Indeed, with the help of various third-party libraries, you could and can use the concept of promises in an ES5 code already. Here's how a promise works in JavaScript.
const getUser = () => {
return new Promise(resolve => {
setTimeout(() => {
resolve({ name: 'Max' })
}, 2000)
})
}
getUser().then(user => {
console.log(user.name)
})The getUser() function might look confusing, focus on the bottom part of the code though. We simply call getUser() there and then use then() to handle the asynchronous value. Inside getUser(), we create a new promise. The constructor function of that object receives a function as an argument. That function is executed automatically and can also receive two arguments: resolve and reject. Both are function you may execute inside the function passed to the promise constructor.
When calling resolve(data), you resolve (= complete) the promise and return data to the function executed in the then block.
You could also call reject(err) to throw an error. I'll come back to error handling later.
It might not immediately look that much better than callbacks but consider that we only use one asynchronous operation here! The real power of promises can be seen once we start using dependent async operations.
checkAuth()
.then(authStatus => {
return getUser(authStatus) // returns a new promise which may use the authStatus we fetched
})
.then(user => {
console.log(user.name) // prints the user name
})This code is much more readable than its callback alternative! And of course this argument gets even stronger once we start chaining more async operations. Inside then(), you can simply return the result of a function call. And the result of that function call can be used in the next then() block - you'll receive it as an argument there. If the returned result is a promise, JavaScript will wait for its completion and resolve it for you. Awesome!
What about errors?
You can handle errors with ease, too! Simply add a catch() block to your chain and it will catch any errors thrown by any of your promises.
checkAuth()
.then(authStatus => {
return getUser(authStatus) // returns a new promise which may use the authStatus we fetched
})
.then(user => {
console.log(user.name) // prints the user name
})
.catch(error => {
// handle error here
})Promises offer a real improvement over callback functions and they give you a chance of escaping hell which doesn't sound too bad. ES6 also offers some other nice features you can use with promises - you may have a look at Promise.all() orPromise.race() for example.
Are we happy?
Promises are awesome - are we happy then? Maybe. Promises are pretty great and see a lot of usage these days. You can really build predictable and manageable pipelines for asynchronous operations with them. They do have one limitation though: You may only handle one asynchronous operation with each promise. That's fine for sending HTTP requests and reacting to responses for example. It's not really a great solution if you want to handle asynchronous operations which don't end after one "value".
What would be an example for an asynchronous operation which might be run multiple times? Think about user events. They're certainly asynchronous as you can't block your code to wait for them to occur. You can't really handle them with promises though. You could handle one event (e.g. click on a button) but thereafter your promise is resolved and can't react to further clicks.
const button = document.querySelector('button')
const handleClick = () => {
return new Promise(resolve => {
button.addEventListener('click', () => {
resolve(event)
})
})
}
handleClick().then(event => {
console.log(event.target)
})In this example, we're adding an event listener to a button in our DOM. This happens inside the promise but since a promise can only resolve once, we're only reacting to the first click. Subsequent clicks will go into the void. It's this reason as well as one other important advantage which made Observables very popular. Now what's that again?
RxJS Observables
Note: ## RxJS 6 was released! Please note that RxJS 6 was released. Updating is easy and described in detail in this article. For the CDN drop-in import (which we're using in this article), have a look at this example snippet.
Promises aren't bad, not at all! You may very well stick to them and I'll actually come back to promises later in this article. But whilst being relatively new to the JavaScript world, RxJS Observables already gained quite some ground. There are good reasons for that. Here are the two biggest arguments for using observables over promises.
- You're working with streams of data instead of single values
- You got an amazing toolset of operators at your disposal to manipulate, transform and work with your async data
Streams of Data
Let's start with that "streams of data" thing. What exactly do I mean with that expression?
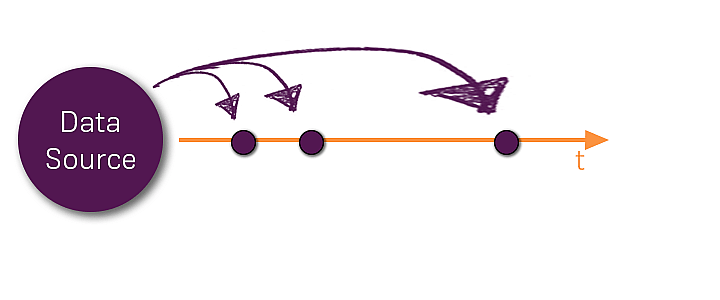
The data source (for example a button getting clicked) may emit multiple values. It could also only emit one - we don't know! Or maybe we do even know that we'll only receive one data object (e.g. HTTP request + response) - this can still be treated as a stream of event(s) and hence we may use RxJS Observables. More about arguments speaking for observables in all kind of situations will follow later.
For now, let's focus on that stream of data. As mentioned earlier, you can't handle that stream just like that with promises. You can do that with observables though. Here's how it could look like.
const button = document.querySelector('button')
const observable = Rx.Observable.fromEvent(button, 'click')This actually doesn't do anything yet (i.e. we don't react to clicks) but we did set up an observable here. As the name implies, an observable observes something. In this case, it observes click events on the button we passed to fromEvent(). You could say that clicks on that button are our data source now.
That's of course nice but not that useful one its own. We want to react to these clicks, right? No worries, we can! We have an observable which is now watching clicks on that button. With that, we can now set up a subscription on that observable.
const button = document.querySelector('button')
const observable = Rx.Observable.fromEvent(button, 'click')
observable.subscribe(event => {
console.log(event.target)
})With subscribe(), we actually subscribe to all the data pieces the observable recognizes. Remember? We do have a stream of data pieces. Whenever a new piece appears, our subscription gets informed. We then react by passing a function as the first argument to subscription(). We can pass two other functions but I'll come back to these. In the first function we pass, we receive the data for each data emission the observable recognizes. Put in other words: The function we pass to subscribe() gets executed whenever a new value is emitted. In our case, whenever the button gets clicked.
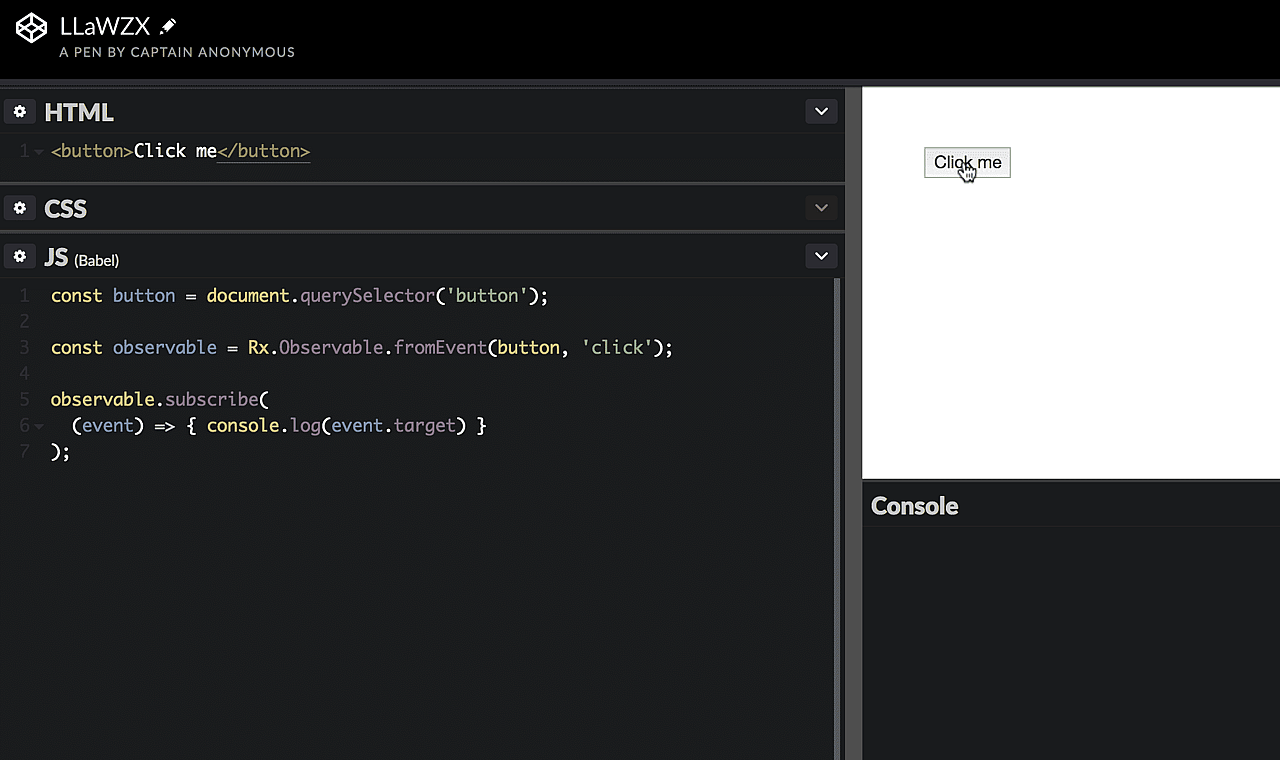
Check this pen to run it yourself.
Being able to react to an infinite amount of asynchronous (or also synchronous!) stream of data is pretty awesome. As you can see, you also have a very clean and simply syntax. You can also listen/ react to two other things: Errors and completion.
Errors
If your observable data source emits an error, you probably want to react to that. An example would of course be a HTTP request which errors out. In promises you had catch(), with observables you may simply pass another function to subscribe().
observable.subscribe(
event => {
console.log(event.target)
},
error => {
console.log(error)
} // <- Handle the error here
)Of course this doesn't make much sense for an observable watching button clicks. This can't throw an error. But many data sources (e.g. HTTP requests, validation, authentication) can throw errors. In such cases, the second function passed to subscribe() gets fired - you can implement any logic you want to handle errors inside that function.
Completion of an Observable
Some, but not all, observables also complete eventually. Our click-watching observable doesn't. How would it? You don't know if the user is going to click again or not. Other observables do complete though. The good old HTTP request does for example. In such a case, the first function passed to subscribe() still gets fired as described above. You can handle the emitted value there. But additionally, a third function gets executed - if you provided it.
observable.subscribe(
event => {
console.log(event.target)
},
error => {
console.log(error)
},
() => {
console.log('Completed!')
} // <- Gets executed once the observable completes - it doesn't receive any argument, no data
)This third argument receives no data, it simply is a place where you can execute any code you want to execute once you know that the observable finished.
These are the basics about observables and you can probably already see why they might be an useful alternative to promises and callbacks. But what do you do if the observable returns a new observable? When using promises, you could simply chain then() calls to handle promises resolving new promises. How does that work for observables? And what about that second big advantage I outlined earlier - the many operators?
Observables & Operators
As mentioned before, another big advantage of observables are the many operators you can use on them. Thus far, we haven't used any though. subscribe() isn't really a special operator but a vital tool to get any use out of observables.
Let's go back to the issue of observables returning new observables. Have a look at the following code.
const button = document.querySelector('button');
const observable = Rx.Observable.fromEvent(button, 'click');
observable.subscribe(
(event) => {
const secondObservable = Rx.Observable.timer(1000);
secondObservable.subscribe(
(data) => console.log(data); // <- Back in callback hell?
);
}
);Here, we create a new observable on every click. This observable will then emit one (and only one) value (0) after 1 second. It works fine but to me, it looks a lot like callback hell. Are observables just a more elegant way of getting there? Not at all! We just have to use one of the amazing operators the RxJS library ships with: switchMap().
const button = document.querySelector('button')
const observable = Rx.Observable.fromEvent(button, 'click')
observable
.switchMap(event => Rx.Observable.timer(1000)) // <- use the data of the first observable in the second one (if you want) and return the new observable
.subscribe(data => console.log(data))Here's a link to the codepen.
Isn't that beautiful code? We easily map the value of our first (outer) observable into a new (inner) one. We could use the data (in our case the event object) there if we wanted. In the example, we ignore it and instead simply return a new observable which fires after 1 second and returns 0.
There are way more operators than just switchMap() and it are these operators which give observables a clear edge over promises - even in cases where you don't really work with a stream of data (like the famous HTTP request). You can simply treat everything, even synchronous data, as a stream and use the awesome operators. Consider this example.
const observable = Rx.Observable.of({ name: 'Max' })
observable.pluck('name').subscribe(data => console.log(data))Here's the code.
This example doesn't have anything asynchronous about it - we simply use RxJS observables here to easily retrieve a value out of an object. Of course there are easier ways to achieve the same result - but keep in mind it's a trivial example. The key takeaway is: Observables are awesome due to their data-stream nature and observables. For both async and sync data.
Async & Await
We found the clear winner, didn't we? Observables own everything. Well, observables are amazing and I can only recommend using them. But if you're dealing with an issue where the operators don't help you (even though that's hard to imagine), you might not really face a disadvantage when using promises.
There's one thing which can be annoying when using both promises or observables: You're writing code "in block", not like you normally do. Wouldn't it be nice if you could write async code just like you write synchronous one? Like that?
auth = checkAuth() // <- async operation
user = getUser(auth) // <- async operation
console.log(user.name)That would be nice but it's of course not possible due to the way JavaScript works. It doesn't wait for your asynchronous operations to finish, hence you can't mix them with your synchronous code like that. But with a new feature added by ES8, you suddenly can!
async function fetchUser() {
const auth = await checkAuth() // <- async operation
const user = await getUser(auth) // <- async operation
return user
}
fetchUser().then(user => console.log(user.name))In the example, you see that we still use then() to react to the data passed by our promise. But before we do that, we actually use two promises (both checkAuth() as well as getUser() return a promise!) to fetch a user. Even though we work with promises here, we write code just like we write "normal", synchronous code. How does that work?
The magic happens via two keywords: async and await. You put async in front of a function to turn it into an async function. Such a function will in the end always resolve as a promise - even though it doesn't look like one. But you could rewrite the example like this.
function fetchUser() {
return checkAuth()
.then(auth => {
return getUser(auth)
})
.then(user => {
return user
})
}
fetchUser().then(user => console.log(user.name))This also gives you a clue about what await does: It simply waits (awesome, right?) for a promise to resolve. It basically does the same then() does. It waits for the promise to resolve and then takes the value the promise resolved to and stores it into a variable. The code after await checkAuth() will only execute once it's done - it's like chaining then() calls therefore.
What about handling errors? That's pretty easy, too. Since we're now writing "synchronous" code again (we aren't), we can simply use try-catch again.
async function fetchUser() {
try {
const auth = await checkAuth() // <- async operation
const user = await getUser(auth) // <- async operation
return user
} catch (error) {
return { name: 'Default' }
}
}
fetchUser().then(user => console.log(user.name))Async/ await gives you a powerful tool for working with promises. It doesn't work with observables though. The reason being that behind the scenes, async/ await really only uses promises.
Which Approach Should You Use?
We had a look at four different approaches:-Callbacks with the danger of entering callback hell -Promises to escape callback hell-Observables to handle streams of data and apply operator magic -async/ await to write "synchronous" code with promises
Which approach should you use?
Use Callbacks if you got no other choice or only handle one async operation. The code will then still be perfectly manageable and understandable. Callback functions aren't bad per se - there just exist better alternatives in many cases.
One such case are multiple chained (or dependent) asynchronous operations. You quickly enter callback hell when trying to use callbacks in such a situation. Promises are a great tool to handle your operations in a structured and predictable way.
In all cases where you use promises, you might also use observables. It's not strictly better but if there's an operator which makes your life easier or you simply love observables, there's no downside in using them. There's a strong argument to be made for observables once you handle data streams, i.e. operations where you're not just getting back one single value. Promises can't handle such situations (easily).
Finally, async/ await is an awesome tool for cases where you don't really want or need to use observables but still want to use promises. You can write "synchronous" code with async/ await and handle your promise chains even easier.
Ultimately, it of course also comes down to your taste and the environment you're working in. For everything but callbacks, you'll probably need a transpiler and/ or polyfill. If you only target environments where ES6 or even ES8 is supported natively, that's not true anymore. For observables, you'll always need the RxJS library - that of course means that you'll increase the codebase you ship in the end. Might not be worth it if you're only handling trivial cases.
I hope this article could shed some light on these tools and when to use which of them. Let me hear your thoughts - on this article or on any of these tools.