JavaScript - The Tricky Parts
JavaScript is a powerful language, but it got a couple of "pain points". From my experience as an online instructor, I could identify nine main areas where a lot of JavaScript developers struggle - or can learn more:
- Scope & Hoisting
- Loops
- Primitive & Reference Values
- Closures
- Recursion
- Callbacks (Indirect vs Direct Function Execution)
- Asynchronous Code
- The 'this' Keyword
- Prototypes
Of course, the language also has a couple of other difficult elements and in general, learning a programming language (and mastering it) is a challenging task. But I got my JavaScript - The Complete Guide course for that - there, you learn JavaScript from the ground up, step by step.
For now, let's focus on those "special" parts of JavaScript which sometimes can be confusing.
Note: This article deliberately provides a brief summary of these concepts. This might be all you need and want. If you do want to dive deeper and see some edge-cases, too, you can dive into my JavaScript - The Tricky Parts course.
Scope & Hoisting
Scope controls the "visibility of variables" in your code (i.e. which variable can you use where), hoisting can mess with your code order.
With incomplete knowledge about these concepts, you might fail to understand why the following code snippet works the way it works:
let result = 1;
console.log(addOne(3)); // outputs 4
console.log(result); // outputs 4
function addOne(numToAdd) {
result = result + numToAdd;
return result;
}In this snippet, we got both concepts at work.
Scope is all about the visibility of variables in your code - it controls which variable can be used where.
JavaScript knows three types of scope:
- Global Scope: Variables defined outside of any function or other block statement like
if - Function Scope: Variables defined with
varinside of a function - Block Scope: Variables defined with
letorconstin any block (likeif,foretc.)
A variable can only be used in its scope and any nested scope.
That's why, in the above example, result can be used inside of addOne() even though it's not declared or defined inside that function.
It is declared and defined globally and hence has global scope (or, since it's defined with let, actually block scope - but it behaves similarily here) and with that scope, it can be used anywhere in your script, including functions.
If the variable would be declared inside of a function (which also is a "block" at the same time), it would only be available in there:
console.log(addOne(3)); // outputs 4
console.log(result); // Error!
function addOne(numToAdd) {
let result = 1; // result now has block scope
result = result + numToAdd;
return result;
}To learn more about scope (e.g. how it behaves when using JavaScript modules), you can dive into my course.
Hoisting is about how the JavaScript engine parses and executes your code and the "availabililty" of functions and variables.
In the above snippet, we call addOne() even though the function is only declared after the line where we execute it.
This works because of this concept called hoisting.
For function declarations (i.e. the syntax used above), you can call the function before its declared because JavaScript "memorizes" that function before it actually starts executing your code.
You can think of hoisting being a feature that is based on two 'phases' of code execution:
- Compile Phase (where code is also analyzed and functions are memorized)
- Execution Phase (where the code is then executed)
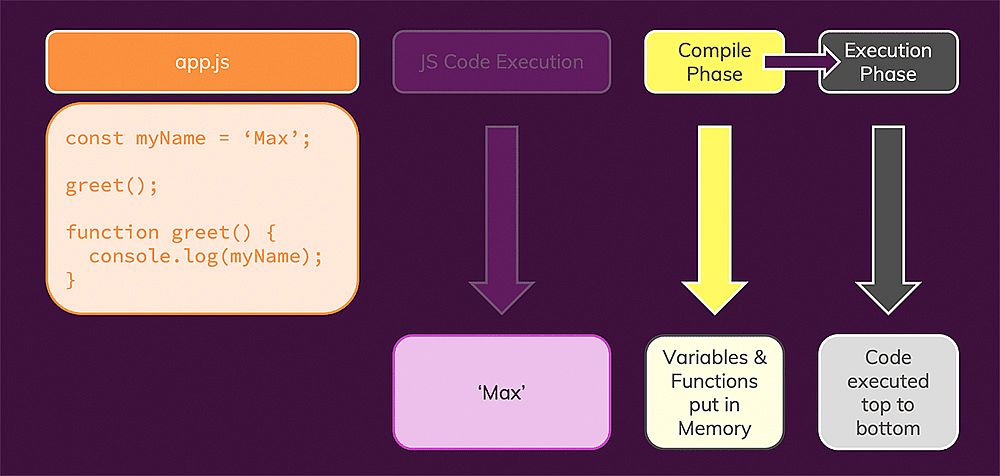
Hoisting behaves differently for function declarations, function expressions and variables but you can learn all about that in my course.
Loops
Loops are simple, right?
You have code and you execute that code multiple times - until a certain condition is met (while, for) or until you're out of elements (for-in, for-of).
Generally: Yes.
But there are a couple of "interesting cases".
For example, did you know that for-in can be used on an array, too? It just might not be what you're looking for.
But even if you stick to objects, did you know that you can get unwanted properties as part of the loop?
Consider this code:
const person = Object.create({ group: 'users' });
person.name = 'Max';
person.age = 31;
for (const key in person) {
console.log(key);
}This snippet will output three keys instead of just two: group, name and age. Because inherited properties are included.
You can use hasOwnProperty() to avoid this.
for (const key in person) {
if (person.hasOwnProperty(key)) {
console.log(key);
}
}But that's just one thing.
It's also worth pointing out that for-of can be used not just on arrays but actually on any iterable (e.g. sets, maps). You can't use it on objects though.
Or did you ever wonder why you use let in a regular for loop but const for for-in and for-of?
for (let i = 0; i < 3; i++) {
console.log('i: ' + i);
}
for (const el of [1, 2, 3]) {
console.log('Element: ' + el);
}The idea here is, that the "normal" for loop uses one variable which changes with every iteration. The for-of loop on the other hand creates a brand-new variable for every element that's in the array.
It is recommended that you use const whenever possible though, hence it's important to know that this is not a good idea (i.e. you'll get an error) for normal for loops.
These are some of the JavaScript specialities worth knowing (and understanding).
Primitive & Reference Values
Primitive values (or: "Primitives") and reference values are core concepts which are often misunderstood (or worse: unheard of).
JavaScript knows 6 (or 7, if you add null) primitive values:
- String
- Number
- Boolean
undefined(andnull)- Symbol
- BigInt
Primitive values are immutable and shared by copy.
What does that mean?
Let's take a look at a short code snippet:
let number = 1;
console.log(number + 2);
number = number + 3;The value stored in number (i.e. NOT the variable itself!) is never changed, only the variable is.
The value stored in number (initially) is 1 and it stays 1.
console.log(number + 2) copies number and calculates a new result (3) which is then output.
number = number + 3 does the same: It copies number, derives a new result (4) and then stores that new result in the number variable. The number that was used (1) is simply dumped - but it's never changed.
This might sound trivial or redundant but it's a core concept of JavaScript. And it's the opposite of what happens with reference values.
There is just one single reference value in JavaScript: The object. Though keep in mind, that arrays and functions are also objects in JavaScript!
Unlike primitives, reference values ARE mutable and are shared by reference.
const person = { age: 31 };
const me = person;
person.age = 32;
console.log(me.age); // prints 32!In this snippet, we output 32 even though we changed person.age, NOT me.age (keep in mind that we output me.age!).
Why does that work?
Because we don't copy the value stored in person when we assign it to me. Instead, just a pointer (address, reference) to one and the same object in memory is copied, NOT the value in memory (i.e. the object) itself.
So we got two variables pointing at the same object in memory.
In addition, as mentioned, reference values are mutable, so we can manipulate them. In this case, we change an existing property (age) but we could've also added a brand-new property (or method) to the object.
person.name = 'Max'; // you can do that, even though 'name' didn't exist on the object beforeThat's also why we can use const here. We never assign a new value to the person variable (constant). That always stays the pointer to the same object in memory.
We just change that object in memory but this of course does not affect what's stored in the constant: The pointer (reference).
Closures
What's a "Closure"?
Every function in JavaScript is a closure!
That means that every function closes over its environment when it's created.
The "environment" is basically a meta data store with information about the available variables and a few other things. In my course I dive deeper into environments, contexts, scope etc.
Consider this example:
let myName = 'Max';
greetMeWithDelay();
myName = 'Maximilian';
function greetMeWithDelay() {
setTimeout(function() {
console.log('Hi ' + myName);
}, 1500);
}Will this output Max or Maximilian? Or maybe an error because myName is defined outside of the function?
We get Maximilian and that could actually be strange. After all, we call the function before we change myName to Maximilian.
That's a closure in action.
For one, we're able to use myName inside of the anonymous function passed to the timer because of scope.
But in addition, we're also able to use myName "in the future" (when the timer exired) because every function forms a closure in JavaScript.
The anonymous function "memorizes" all variables in reach when it's created (i.e. when the timer is set).
And when it then executes (i.e. when the timer expired), it still has access to those variables.
That's the essence of a closure.
But there is one important thing! The variable itself is memorized, not the value.
That's why we output Maximilian - because the value is only looked up when its needed, not when the closure is created!
There also are some tricky interview questions that are sometimes asked in relation to closures - I cover one of them (a for loop with a timer) in my course.
Recursion
Recursion is generally a tricky concept - not just in JavaScript. It can really mess with your mind.
But recursion is actually not toü difficult to get into: It's just a function calling itself after all.
// Beware: This causes an infinite loop!
function callOnMe() {
callOnMe();
}
callOnMe();callOnMe is a (stupid) example for a recursive function. It calls itself from inside the function body.
This snippet would lead to an infinite loop though because we have no way of ending this cycle.
That's why you need two core elements in recursive functions that make sense:
- A base case: Basically a condition that allows you to exit
- A recursive step: The part where you call yourself
function factorial(n) {
if (n === 0) return 1; // base case
return n * factorial(n - 1); // recursive step
}
factorial(3); // 6In this example, we calculate the factorial of a number by using recursion.
The base case is our exit condition: If n === 0, we return a concrete value, we don't call ourself again.
Otherwise, in the recursive step, we DO call ourself again - but with a new value (n - 1).
The previous function execution now waits for this recursive step to complete. And if we call ourself again from the newly invoked function execution, we'll wait for that as well.
JavaScript only executes one function at a time but it's capable of managing multiple ongoing (waiting) function calls with help of a concept called the execution context stack (or "call stack").
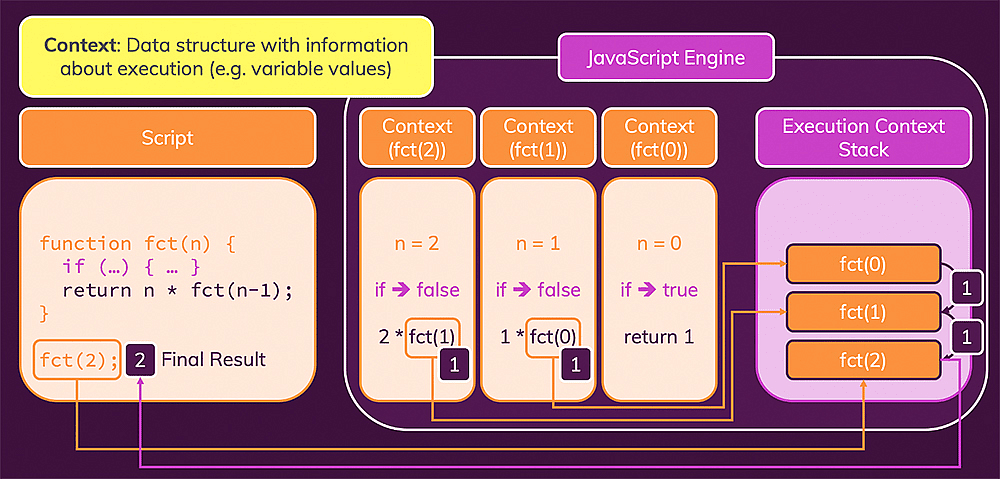
We could've used a loop instead but recursion often allows you to write less code. There also are some problems which are very hard (or impossible) to solve without recursion (e.g. traversing through a tree-like structure, covered in the course).
Callbacks (Indirect vs Direct Function Execution)
Callback functions are used a lot in JavaScript. In the end, a callback function is simply a function that's passed as an argument to another function.
function greet() {
console.log('Hi!');
}
function executeItForMe(cb) {
cb();
}
executeItForMe(greet);In this snippet, greet is passed as a callback function to executeItForMe. The latter is a function that wants a function as a value for its parameter (cb, for "callback", the name is up to you though).
Inside of executeItForMe we do nothing else but call cb(). I.e. we execute the function we received as a value.
This might look redundant but it makes a lot of sense if you think about (built-in) use-cases like event listeners:
const btn = document.querySelector('button');
btn.addEventListener('click', addUser);
function addUser() {
console.log('Adding user...');
}In this example, we "tell" addEventListener to set up a click listener on some button and to then execute the addUser function when that happens.
addUser is therefore passed as a callback function to addEventListener.
I like to call this "indirect function execution" because we don't execute the function on our own, instead we hand off that task to another function.
The opposite would be the "direct function execution":
function sayHello() {
console.log('Hello!');
}
sayHello();Here, we directly call sayHello() on our own.
The difference is the addition of parentheses. When you add them after the name of a function, you execute that function.
Otherwise, you just refer to the function by its name, you don't execute it.
That's why we don't add parentheses on the function passed to addEventListener (and in similar cases). We don't want to execute that function immediately, we just want to pass a pointer (a reference, the address) to that function to addEventListener so that addEventListener can call that function for us when the event occurs.
Now there are some interesting cases when we think about passing arguments to such indirectly executed functions but I cover those both in my course as well as in this article & video.
Asynchronous Code
JavaScript is single-threaded and only capable of doing one thing at the same time.
But in programming, especially when working in the web, we also have many asynchronous tasks (i.e. tasks that don't complete instantly). For example when we send a Http request, set a timer or create an event listener.
How does that work together with JavaScript only being able to do one thing simultaneously?
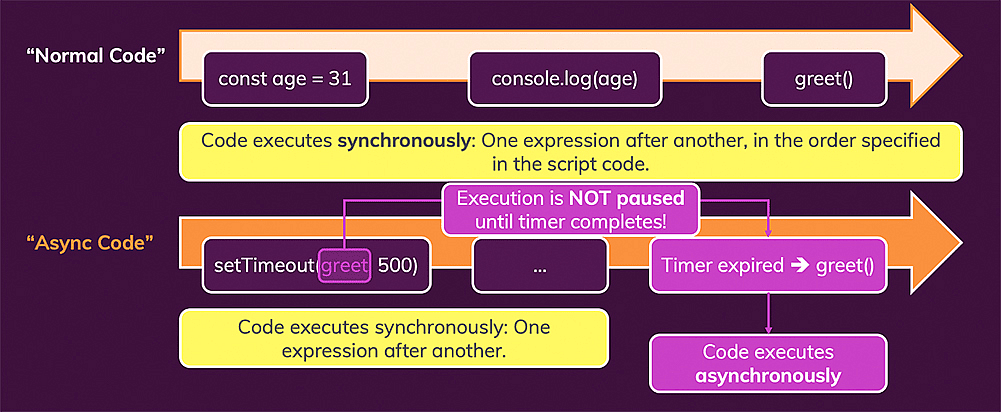
The answer is easy: JavaScript hands of asynchronous tasks to its environment - i.e. to the browser or the NodeJS runtime.
It then just lets this environment know what should be done (i.e. which function should be executed) once the task is done so that it is able to use the "result" of that task.
For that, JavaScript leverages callback functions (see above).
setTimeout(sayHello, 5000); // handed off to the browser
const sayHello() {
console.log('Hi!');
}To make working with multiple, maybe dependent, (asynchronous) tasks easier, JavaScript has a related feature: Promises.
fetch('some-url.com/some-data')
.then(response => {
return response.json();
})
.then(data => {
console.log(data);
})
.catch(err => {
console.log('An error!');
console.log(err);
});Without "Promises", if this would be purely callback-based, you could end up with something like this:
// not the actual API - for a good reason :)
fetch(
'some-url.com/some-data',
response => {
response.json(data => {
console.log(data);
// maybe more levels of nested callbacks here
});
},
err => {
console.log('An error!');
console.log(err);
}
);This is called "callback hell" since it can lead to quite unreadable code. Promises make structuring sequential (async) code/ steps much easier.
Promises give you a structured way of working with multiple dependent steps, that's why all modern JavaScript APIs use them. Older APIs (like setTimeout) don't use them but since you can create your own promises as well, you would be able to create a promise wrapper (example shown in my course).
This structured approach works because a "Promise" is a built-in JavaScript object with two core methods: then() and catch().
Both take callback functions as arguments, then(fn) triggers its fn when the action connected to the promise succeeded, catch(fn) triggers its fn when that action failed.
then() and catch() each return new promises, which is why you can chain those then()/catch() methods.
I dive way deeper into promises in my course but you can also learn more about them here.
The 'this' Keyword
The this keyword can be one of the most confusing things you find in JavaScript.
Consider this example:
const person = {
age: 31,
printAge() {
console.log(this.age);
},
};
const outputInfo = person.printAge;
outputInfo();Did you expect to see 31 in the console?
A lot of developers (coming from other programming languages) would!
But you actually get undefined in the console.
Why?
Because of how this works.
The value this points at is set by the surrounding execution context. And this generally refers to "on what the function was called".
So person.printAge() would've worked because this would be used in a function that's executed directly on person.
When we first store a pointer to that function in another variable (outputInfo), that changes though.
When outputInfo() is executed, it's not called on person.
It's actually called on nothing - it's simply executed in the global script execution context. And there, this refers to the window object in the browser. That window object has no age property, hence we get undefined.
So a good rule of thumb is: this
It gets a bit more tricky in some cases like addEventListener:
const btn = document.querySelector('button');
btn.addEventListener('click', function() {
console.log(this);
});In this example, this would not refer to the window object, even though it's not called on anything.
Instead, this will refer to the element on which the event occurs. But that's just a special thing of addEventListener - essentially, the value of this can be changed when the function is called.
addEventListener does that but you can do that, too - for example with bind:
const btn = document.querySelector('button');
btn.addEventListener(
'click',
function() {
console.log(this);
}.bind({ name: 'Max' })
);In this snippet, this is set to { name: 'Max' } with help of the built-in bind method which you can call on every function object in JavaScript.
This bind method is a method worth remembering because it allows you to control the value of this - something you often need to do in JavaScript.
Prototypes
JavaScript is a language that supports objects and also inheritance - the latter is implemented with the help of a feature called "prototypes".
But what are prototypes?
You could say that every JavaScript object holds a link to another object which is used as a "fallback object" in case some property or method is not found on the original object.
Here's an example:
const names = ['Max', 'Manu', 'Julie'];
names.forEach(name => console.log(name));This snippet prints the three names to the console. Not too spectacular, is it?
Well, it is - at least if you also do the following:
console.log(names);What do you not see in the object that's logged to the console? The forEach() method!
Actually, all array methods (map(), push(), ...) are missing!
Where are they?
They're part of the fallback object which is linked to the array object. For that, keep in mind that an array is created with the built-in Array constructor function (new Array() is the longer form of just []). And that constructor function is configured to link every new array object (arrays are just objects in JavaScript) to another object.
And that other object has all those array methods!
Why is this being done?
Because that avoid a lot of unnecessary memory usage. Having all those methods on every array, regardless of if you need them there or not, would just bloat of all those array objects.
It makes much more sense to have one "utility object" with those methods which then is linked to all created arrays.
And that linking is done with that prototype concept.
Indeed, you can view the prototype object (i.e. the fallback object) by doing this:
console.log(names.__proto__);__proto__ is a non-standard property which every object has. It's non-standard but supported by most browser - still, you shouldn't rely on it and you shouldn't use it for anything else than debugging/ development.
But this property points at the object which is linked to that object.
And that linking continues - it builds the so-called prototype chain. Every object is linked to another fallback object until you reach the built-in "root object" (created with the Object constructor function, which you use when you create objects with the literal notation - {}). This "root object" has null as a prototype.

When you access a method or property that can't be found on the object you're accessing it on, JavaScript automatically goes up in that prototype chain and looks in the next object (and thereafter in that objects's prototype) for that method or property.
As a developer, you can set and change prototypes:
const person = { kind: 'human' };
const user = Object.create(person);
user.name = 'Max';
console.log(user.kind); // works!
Object.setPrototypeOf(user, { kind: 'mammal' });
console.log(user.kind); // works, prints 'mammal'Object.create(obj) is a built-in method that creates a new object which is linked to obj as its prototype. That's why we can access user.kind in the example. JavaScript doesn't find it on user but it then looks on user's prototype (person) and finds it there.
Object.setPrototypeOf(obj, newProto) is another built-in method which allows you to change the prototype of an existing object.
You also got other ways of changing and setting prototypes. One of the most important thing you have to know about is the prototype property on constructor function objects:
const human = { kind: 'human' };
function Person(name) {
this.name = name;
}
Person.prototype = human;
const max = new Person('Max');
console.log(max.kind); // works!With Person.prototype, you set the prototype every new object, that is created with help of Person (new Person()), will have.
And that's important!
The prototype property does not set the prototype of the Person function object itself! You could do that with Object.setPrototypeOf().
Instead, prototype sets the "to-be-assigned" prototype object of objects that are created with help of new Person().
So, in the above example, max has a prototype of human.
console.log(max.__proto__ === Person.prototype); // true
console.log(max.__proto__ === human); // also trueThe non-standard __proto__ property gives you access to the prototype of the object you're accessing it on. The standard prototype property does something different. It points at the prototype of objects that will be created in the future (via the constructor function on which you set it). Hence only function objects have a prototype property.
I do dig a bit deeper into this in my JavaScript - The Tricky Parts course - there, we then also explore how class is related to all of that.